Omic.ly Weekly 68
March 24, 2025
Hey There!
Thanks for spending part of your week with Omic.ly!
This Week's Headlines
1) In silico identification of a side effect free weight loss peptide
2) The proteome is so hot right now
3) Hi-C showed us that the genome has topology
Here's what you missed in this week's Premium Edition:
HOT TAKE: Clinical evidence is still desperately needed to justify the high cost of liquid biopsy based screening tests
The quest to find better tolerated weight loss drugs is well on its way and computational drug discovery has already identified at least one promising candidate!
GLP-1 Receptor Agonists have been all over popular media these last few years.
They’re life savers for diabetics or the severely obese because they promote the secretion of insulin and the proper regulation of blood sugar.
But our bodies do naturally produce glucagon-like peptide - 1 (GLP-1), which is an incretin, hormones secreted by cells in our intestines, pancreas and brain in response to the detection of nutrients.
This results in the binding of GLP-1 to the GLP-1 Receptor (GLP-1R) leading to the release of insulin and other hormones important for regulating blood sugar.
Our natural GLP-1 only acts for 1-2 minutes, so the duration of its effects are limited because it’s quickly broken down in our blood stream.
But we realized that GLP-1s could also be powerful drugs and the first of these drugs to get approved, like Liraglutide (Victoza), lasted a couple of hours and needed to be taken daily.
And because these are peptide based drugs, that meant patients had to inject themselves with something every day which isn’t ideal.
This changed with the introduction of semaglutide (Ozempic) and tirzepatide (Mounjaro) which are once a week injections.
These drugs do come with significant side effects, though, and can cause nausea, vomiting, and aversion to food.
So, the race has been on to find compounds with similar effects on weight loss, but without all of the potential negative side effects.
One good place to start that search is within ourselves.
That's because our bodies are full of small peptides that are the result of prohormone cleavage - GLP-1 and insulin are both examples!
Thinking that maybe there are other important secreted peptides that act on the same pathways as GLPs, researchers took a computational approach (regular expressions) to predict peptides based on the presence of protein cleavage sites.
They developed a program called PeptidePredictor to find secreted proteins that might be cleaved into bioactive peptides and then took some of those peptides and screened them for biological activity
The peptides were chosen “on the basis of metabolic tissue location, size and uncharacterized function.”
They found one, BRP, a 12 residue peptide derived from BRINP2 that increased activity 10-fold and when tested in mice and minipigs they showed that BRP reduces food intake but doesn’t cause nausea or food aversion.
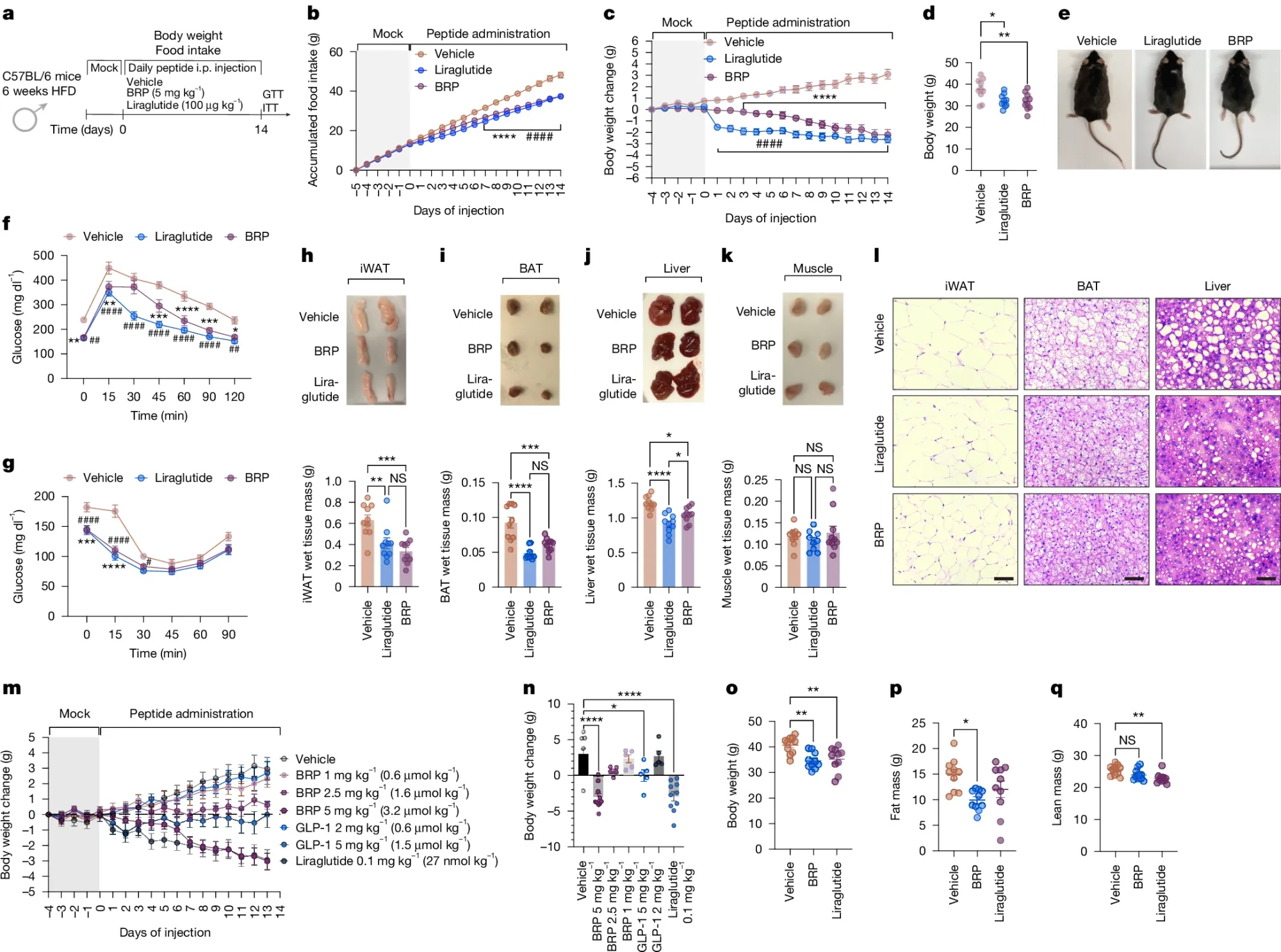
In the figure above, they also showed that BRP can reverse obesity. a) Design of the study with mice on a high fat diet b,c,d,e) BRP and Liraglutide (Victoza) reduce food intake and weight gain, Treated mice also had better glucose (f) and insulin tolerance (g), Treatment reduced white (h) and brown (i) fat. It also reduced liver weight (j) but not muscle mass (k). m,n,o,p,q) the most effective dose of BRP was 5mg/kg.
They went on to show that BRP only activates the hypothalamus and not the brain stem which could explain why it doesn’t have the same negative side effects as GLPs.
They also showed that BRPs effects occur independent of the GLP-1 receptor.
While this peptide appears to be well tolerated, more research needs to be done to identify which receptor it acts through and any other possible side effects that weren’t observed in this study.
But this work does highlight the utility of computational drug discovery in identifying compounds that can have a therapeutic benefit.
###
Coassolo L, et al. 2025. Prohormone cleavage prediction uncovers a non-incretin anti-obesity peptide. Nature. DOI: 10.1038/s41586-025-08683-y
The Proteome: we can’t live without it, but, what actually is it?

It’s pretty simple:
The proteome is all of the proteins that are coded for by your DNA!
However, the process of creating proteins is somewhat complicated and to get to those beautiful, functional, molecules, we actually need to start by talking about the ‘central dogma.’
The central dogma of molecular biology was first theorized by Francis Crick in 1957.
It states that DNA codes for RNA which codes for proteins and once a protein is made, there’s no going back!
You can’t code for RNA, DNA, or other proteins from protein!
Proteins are made through the ‘translation’ of messenger RNA.
This is a process that involves a large protein complex called the ribosome which ‘reads’ the RNA and stitches together protein building blocks (amino acids) to create the final molecule.
But why are proteins so important?!?
Because they’re the molecules in our cells that do all of the work!
They:
1) Form the structural components of our cells
2) As enzymes, they perform the complex chemistry that makes life possible
3) They also do cool things like copy DNA, read RNA to create other proteins or serve as signaling molecules!
Since proteins perform basically all of our important cellular functions, their presence, absence or altered performance is what defines disease.
Presence and absence are pretty straightforward:
If a protein is needed and it’s not there…that’s bad.
If a protein isn’t needed and it's there…that’s also bad.
But altered performance might be something that’s a little tougher to wrap your head around, so let’s talk about how proteins actually work!
Something we mention A LOT in molecular biology is that structure equals function.
The structure of most proteins is highly complex and we define protein structure across 4 levels:
Primary Structure - Sequence of the amino acids that make up the protein.
Secondary Structure - 2-dimensional structure of the protein. This includes the local interactions of amino acids with one another through hydrogen bonds and disulphide bridges. The most common secondary structures are the α-helix and β-sheet.
Tertiary Structure - Overall 3-dimensional structure of a protein that forms once all of the secondary structures fold into their final forms and interact with one another.
Quaternary Structure - Formed through the interactions among multiple proteins to create a functional protein complex. Many proteins work together with friends to do their jobs!
‘Ok, cool story, but what does any of that have to do with the proteome?!’
Because proteomics is the study of how all of the proteins in your cells and tissues interact to perform their cellular functions!
And understanding how those things break, including the impact on protein structure, function or interactions with their friends, is how we can use proteomics to predict and prevent disease!
While chromosomes are usually depicted as X's, they actually spend most of their time jumbled up like a giant ball of yarn.
Friedrich Miescher first discovered nuclein (DNA) in the early 19th century, and determined it was bound to proteins.
But it was Walther Flemming in 1889 who suggested that this DNA-protein complex be called chromatin - which is the material that makes up our chromosomes.
Don’t be fooled, though.
Just because chromatin was described and named in the 1800’s, that doesn’t mean anyone actually understood what it did!
It took until 1950 for scientists to finally begin to understand that the ‘genetic’ material was DNA.
And it wasn’t until the 1960’s that we first started piecing together how chromatin actually functioned.
To this day, we’re still not entirely sure!
But the classical depiction of our genetic material as ‘rods’ or ‘X’ structures in many introductory biology textbooks is not totally accurate.
This is because these structures only appear when chromosomes ‘condense’ during cell division!
The vast majority of the time, most of our chromosomes are unwound in the nucleus and tangled together in a giant mass.
You might be wondering if the interweaving of our chromosomes in the nucleus plays an important role in regulating which genes are expressed?
And the answer to that question is:
You bet your chromatids it does!
While it had been hypothesized for many years that long-range interactions played an important role in gene expression, it wasn’t until 2009 that these chromosomal contacts were first characterized genome-wide.
Previous work using a technique called chromosome conformation capture or 3C had shown that regions of chromatin could form ‘loops’ or touch each other at long distances.
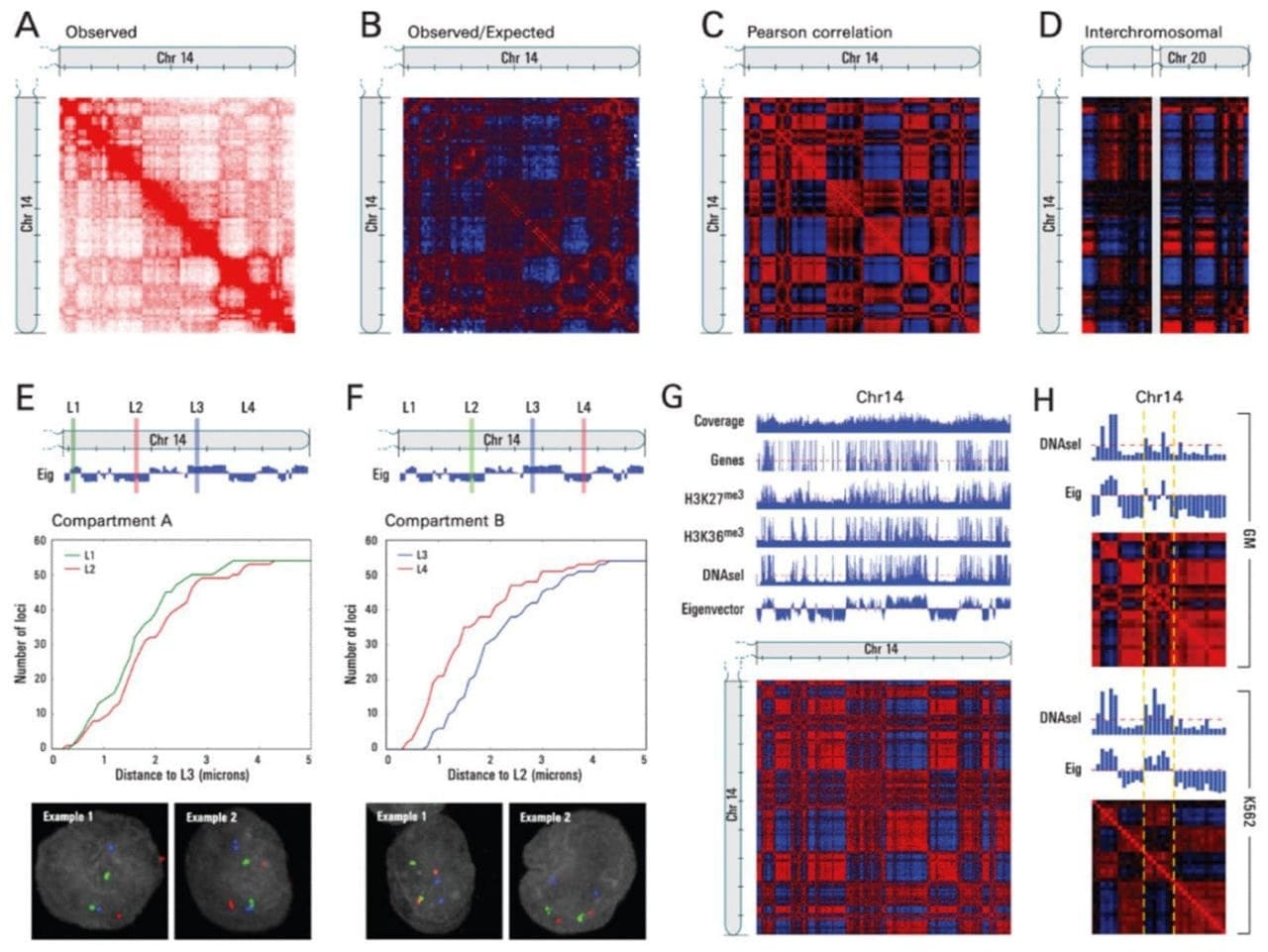
But in this week's figure, the authors mapped chromosome contacts using a technique that they named Hi-C.
It differed from previous chromosome conformation capture methods in that it was the first to leverage high throughput sequencing to look at ALL of the connections within and between chromosomes to map the three-dimensional structure of the genome.
And what they found was really cool!
A) Shows a heat-map of interactions across chromosome 14, B) highlights areas of more contact than expected (red) and less contact than expected (blue), D) shows interchromosomal interactions between chromosome 14 and 20, E and F) highlight how linearly distant regions can actually be in very close proximity to one another, and G and H) show how this architecture correlates with gene rich, open and closed regions of chromosomes!
So, why are these results important?
Because they showed us how the physical three dimensional structure of our genome can impact gene expression, adding yet another regulatory layer to the story of epigenetics.
###
Lieberman-Aiden E et al. 2009. Comprehensive mapping of long range interactions reveals folding principles of the human genome. Science. DOI: 10.1126/science.1181369
Were you forwarded this newsletter?
LOVE IT.
If you liked what you read, consider signing up for your own subscription here: