Fred Sanger, the father of DNA sequencing, cut his teeth doing protein sequencing and snagged a Nobel in the process!
Fred Sanger received a Nobel Prize for his work with Insulin. As the father of DNA sequencing, this surely was for insulin's nucleic acid sequence? It wasn't.
DNA sequencing was his second Nobel.
His first was for the amino acid sequence of insulin.
To say Sanger was an accomplished scientist is an understatement and, unfortunately, his early work sequencing insulin doesn't get nearly the attention that it deserves.
But the experiments leading up to this Nobel worthy achievement began in 1943.
As a new member in Charles Chibnall's group at Cambridge, it was suggested that Sanger focus on exploring the amino acid composition of insulin.
At the time, insulin was basically the only highly purified protein available due to its use in treating diabetes.
It was pure luck that insulin was a small protein, but, as is usually true, small packages can be deceiving, and it took 12 years for him to determine its complete sequence.
The majority of this work was done by tagging proteins on the N-terminus using fluorodinitrobenzene (FDNB) followed by acid hydrolysis and/or trypsin digestion and then separation in two dimensions - first by electrophoresis and then by paper chromatography.
Or, more simply, FDNB turns proteins yellow. Sanger then chopped them into smaller fragments, and the separation technique allowed him to count which amino acids appeared in each fragment and to deduce their order.
The final protein sequence was stitched together by lining up all the overlapping sequence fragments.
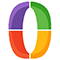
Sanger discovered Insulin has an A chain and a B chain. He sequenced the B chain first, and published that 30 amino acid sequence in 1951.
The 21 amino acid sequence of the A chain wasn't completed until 1952, mostly because it has an intramolecular disulphide bridge that made sequencing it difficult.
The figure above is the culmination of years of hard work that had to be completely redone using slightly different methods that played nicer with disulphide bridges, but this allowed for the identification of their location within the sequence.
The figure below shows the amino acid sequence of both A and B chains of insulin along with the 3 disulphide bridges (S-S) - one intramolecular within A and two others that connect chain A to chain B.
Importantly, this work settled a debate about the structural nature of proteins which, among some scientific circles, was believed to be somewhat fluid.
Sanger showed that insulin had a specific amino acid sequence and, by extension, this was likely true for all proteins.
This seemingly minor detail is what set the stage for Crick's 1958 hypothesis for how DNA codes for proteins.
Surprisingly, the 'Sanger' DNA sequencing method that we all know and (mostly) love wasn't actually developed until 1977!
Read the full issue of Omic.ly Premium 13
 Brian Krueger
Brian Krueger